
Mãe é quem clica: estamos parindo crias do chupadados
Por Tatiana Dias, Joana Varon e Lucas Teixeira
Colaboração Natasha Felizi
Nossa navegaçao é monitorada em várias camadas diferentes. Essa vigilância alimenta um mercado lucrativo de perfis baseados em estereótipos, e mulheres grávidas são as que valem mais dinheiro.
Mulher, cerca de 30 anos, moradora de uma grande cidade, interessada em tecnologia, notícias e política, possível compradora de roupas e artigos para casa. Esse era o perfil de Fernanda até que o teste de farmácia deu positivo. Antes mesmo que o exame de sangue confirmasse e que ela avisasse a família, porém, o mercado online comemorava a boa notícia, tentando empurrar goela abaixo uma série de produtos destinados a mães e bebês em anúncios na internet.
"Aos poucos foi sumindo tudo da timeline do Facebook que não fosse sobre gravidez", ela conta. Ela virou apenas mãe, e todo o universo na internet que ela via remetia às cenas maternas. "Amigas grávidas com quem não tinha contato há tempos começaram a aparecer na minha timeline."
E não foi só isso. No Spotify, uma das sugestões foi uma música com o nome da filha dela. O nome também apareceu em propagandas personalizadas que ela viu pela web. Ela conversava sobre um assunto com alguém - como o dia em que falou sobre um kit berço - e o anúncio apareceu na timeline.
Depois que sua filha nasceu, a natureza dos anúncios mudou. Começaram a pipocar na timeline de Fernanda reportagens sobre a síndrome da morte súbita infantil, terror das mães de primeira viagem por ser uma doença sem explicação e prevenção, seguidas de equipamento para monitorar o sono do bebê. Eles dividiam espaço com propagandas do tipo "mamãe sarada" e "reconquiste seu marido após o filho".
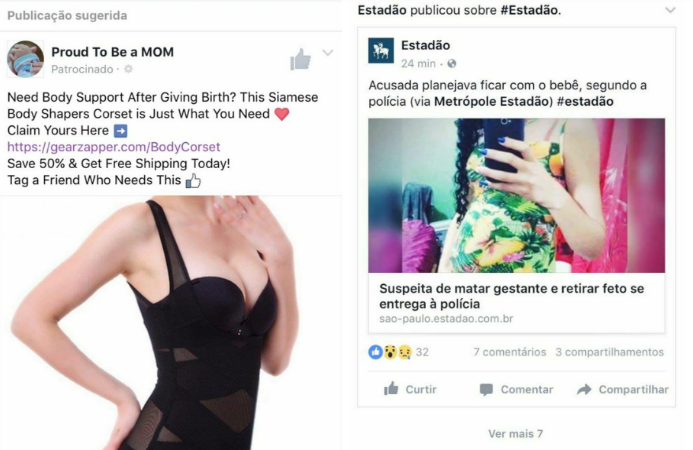
Propaganda de corset pós-gravidez, pressupondo que, depois de parir, você deve entrar na paranóia do corpo "perfeito". E propaganda de quando o algoritmo dá errado: filtra o termo "gravidez" para te mostra tragédias com bebês.
É isso o que boa parte sociedade, ou pelo menos daqueles que moldam os algoritmos do Facebook e outras ferramentas de marketing direcionado, pensam que interessa às mulheres que acabaram de ter filhos - e o conteúdo exibido online, pensado e moldado segundo critérios complexos de personalização, é um reflexo dramático disso.
Cada vez mais nossa experiência na internet é personalizada segundo nossos cliques, histórico, compras, conversas e coisas que a gente nem imagina. E, no caso de uma mudança grande na vida - como a chegada de um bebê - fica muito claro como serviços online e anunciantes usam truques, que muitas vezes não conhecemos, pra exibir coisas que pensam que a gente vai gostar nessa ~nova fase~.
Tchau mulher, olá mãe
Interessa às empresas enquadrar as pessoas em perfis específicos de consumo - especialmente em fases de maior tendência à compra, como é o caso da maternidade. Grávidas estão em uma posição de maior vulnerabilidade em relação ao consumo. O mercado sabe disso, é claro. Na era do Big Data, estima-se que cada consumidor padrão valha US$ 0,10; as grávidas valem US$ 1,50.
O cálculo é da socióloga americana Janet Vertesi. Em 2014, ela mostrou - através de um experimento na própria pele - que a única maneira de esconder a gravidez da internet é apelando para navegação anônima com Tor. Qualquer escorregada na navegação não anônima - uma passada pelo fórum Baby Center ou uma busca por "ultrassom morfológico", por exemplo - já serve para que a mulher seja enquadrada como grávida. E, uma vez perfilada, as empresas não pouparão esforços para conquistar aquela consumidora com o anúncio mais direcionado possível. As chances de ela ser convencida pela propaganda são grandes.
"Eram propagandas relacionadas a identidade", diz Fernanda. Faz todo sentido, porque mulheres passam por um processo de reconstrução da identidade própria após o nascimento de um filho. O marketing sabe disso. Faz parte do processo de perfilamento - ou profiling, em inglês - procurar caixinhas com padrões de comportamento para tentar enquadrar as pessoas, entregando o que elas possivelmente querem. Ou o que acham que elas querem.
O problema é que, com a Internet, o nível de detalhamento e poder persuasivo das propagandas vai a níveis cujas consequências ainda são desconhecidas. Anunciantes podem saber, por exemplo, em que semana de gestação a mulher está, ou se alguém tem tendência à depressão. Esse nível de detalhamento só é possível porque há ferramentas bem sofisticadas de monitoramento que acompanham praticamente tudo o que se faz online. Tudo mesmo.
Por onde for vou te rastrear
Há diversos níveis de monitoramento. Os mais óbvios deles são em ferramentas utilizadas pelos usuários. Até junho de 2017, por exemplo, o Google acessava o conteúdo de seus e-mails para oferecer propagandas relacionadas aos assuntos sobre os quais você tem conversado. O Facebook mostra anúncios relacionados a várias de nossas atividades na plataforma: nossos likes, os likes de nossos amigos, nossos posts e interesses mostrados abertamente.
Mas as empresas também têm outra forma de coleta de dados, mais sutil e quase imperceptível ao usuário comum, que rastreia os sites que você navega pela internet (o tempo que passou neles e até por onde seu mouse rolou) e as compras que gostaria de fazer (não é por acaso que aquele tênis que você namora te persegue internet afora. Vai que uma hora você se convence, né?).
A facilidade das interfaces e a mística metáfora da "nuvem" nos fazem pensar que algum passe de mágica acontece e transporta dados de um lado para o outro. Não é mágica: é um caminho e ele está repleto de pequenos espiões.
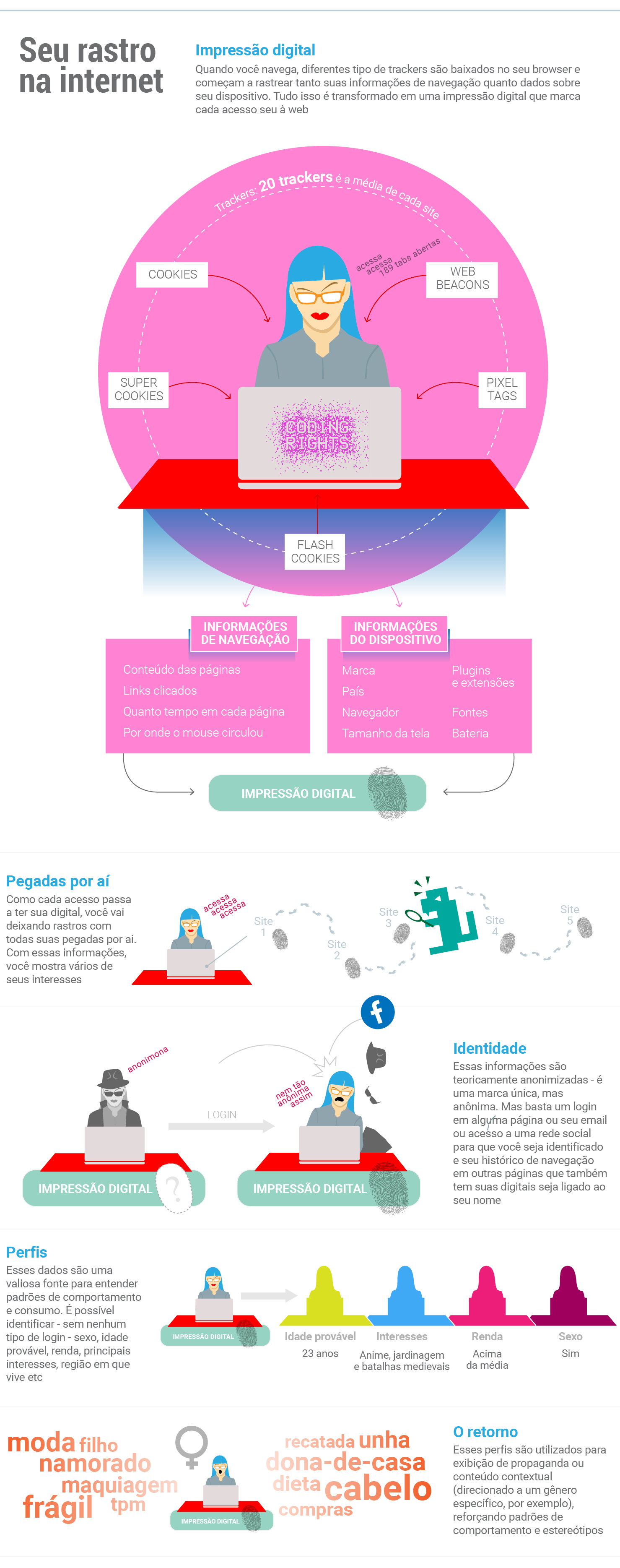
Cada vez que você acessa uma página, um monte de informações extras vão junto no pacote: a versão do navegador e seus plugins, a região de onde você está acessando, e até a posição do giroscópio do seu celular. Essa coleta desenfreada não é causada necessariamente pela maldade das pessoas - mas, sim, pelo desenvolvimento da Internet, que sempre priorizou a adoção de novas tecnologias em detrimento da privacidade. Essas informações, no entanto, foram se mostrando bastante valiosas para a indústria, que conseguia ter uma boa noção de quem estava do outro lado da tela.
Mas essa coleta não para por aí. Programas "trackers" conseguem extrair uma vasta gama de outras informações sobre você e sua navegação.
Assim, quando Fernanda acessa um site, seu navegador não só baixa o texto e as imagens da página, como também executa uma série de programas embutidos no site em forma de arquivos javascript, flash e outros formatos de script. Esses programas conseguem ter acesso e processar dados tanto da própria página (para criar animações, efeitos e funcionalidades) quanto do sistema de seu dispositivo e mandar esses dados de volta para o site. Isso tudo é usado pelas empresas de tracking para monitorar as atividades de Fernanda online.
 Crédito da infografia: Daniel Roda, Joana Varon e Tatiana Dias
Crédito da infografia: Daniel Roda, Joana Varon e Tatiana Dias
Um estudo recente dos pesquisadores Steven Englehardt e Arvind Narayanan, da Universidade de Princeton, jogou alguma luz sobre os atores dessa indústria. Analisando 1 milhão de sites do mundo - os maiores em número de visitantes, segundo o ranking do Alexa -, os pesquisadores encontraram dezenas de milhares de diferentes scripts. Um pequeno grupo de empresas (como Google, Facebook e Twitter) está presente em uma grande quantidade dos sites - o que indica que essa indústria é dominada por poucos atores de peso.
Se o nível de informação que se pode extrair dos navegadores já é perigoso, nos aplicativos de celular a situação é mais crítica, já que a as permissões de acesso a várias informações do dispositivo tendem a ser ainda mais amplas (“mas por que esse app de lanterna quer permissão para acessar a minha agenda???”). Além disso, informações podem estar sendo coletadas quer o aplicativo esteja aberto na tela ou não.
Também há evidências que empresas também estejam monitorando o que escrevemos em mensagens privadas no Whatsapp e até o que falamos perto dos microfones dos nossos celulares ou computadores (ou, no pior dos casos, seguindo a tendência de se multipliacarem dispositivos da chamada "Internet das Coisas", até em casa.
Fernanda e o marido, aliás, viam os mesmos anúncios relacionados - ~coincidência que parou de acontecer quando os dois desligaram o microfone do aplicativo do Facebook de seus celulares.
Anônimo, mas só até certo ponto
As empresas garantem que a coleta dos dados é sempre feita de forma anônima, mas é possível identificar um usuário específico no meio da multidão. Quando Fernanda faz uma conta em uma plataforma e dá seus dados pessoais, ou insere seu número de celular em um aplicativo, é fácil entender que seus acessos e ações estão atreladas ao seu perfil. No entanto, as empresas que fazem as plataformas de monitoramento desenvolveram formas de identificar pessoas na web sem que elas sequer façam login. E, de novo, esse monitoramento é feito através deles: os trackers. Não é por menos que estima-se que cada site tem, em média, 20 trackers rastreando as atividades dos usuários.
Através de uma técnica chamada de fingerprinting, os trackers fazem - como o nome sugere - uma "impressão digital" de todos os dados que conseguem juntar sobre o navegador - versão, tamanho da tela, plugins, extensões, APIs etc. Essa impressão digital permite saber que quem está entrando no site X é a mesma pessoa que entrou em um site Y. É desta forma que é possível saber que Fernanda é mulher, mãe, também gosta de tecnologia e costuma fazer compras online. Basta fazer login em um dos sites onde ela tenha se cadastrado e puf, já é possível atrelar seu histórico de navegação de todos os outros sites ao seu nome de usuário de onde fez um login.
A princípio, estas informações parecem banais e inúteis. No entanto, é consenso na comunidade técnica e na ciência da computação que até mesmo poucos dados que se refiram aos hábitos ou comportamentos de uma pessoa, quando combinados, podem identificá-las com alta precisão, ou destacá-las na multidão com base em características coletivas como etnia, situação econômica, condição de saúde e posições políticas.
“Há somente 6,6 bilhões de pessoas no mundo, então são necessários somente 33 bits de informação sobre uma pessoa para determinar quem ela é”.
Arvind Narayanan, pesquisador, em seu site pessoal dedicado à (des)anonimização de dados
Há um conjunto de técnicas, ainda, que permite que se cruzem informações entre diferentes dispositivos (o chamado cross device tracking). Elas servem para mostrar, por exemplo, que aquela visita ao site em um laptop veio daquela mesma pessoa que usou o celular para pedir um táxi - e, também, para exibir o mesmo anúncio nos dois aparelhos.
Perfis à venda
Determinar quem é o público é a melhor maneira de ganhar dinheiro com ele. E o profiling é uma das técnicas mais utilizadas para isso, porque padrões e tendências podem ser extraídos com facilidade de um grande volume de informações através de mineração de dados.
A grosso modo, os perfis não identificam ninguém individualmente, mas são usados para encaixar pessoas em categorias. Elas podem ser previamente determinadas por quem programa o algoritmo – uma abordagem top-down – ou então emergir de correlações feitas cruzando atributos de um ou mais bancos de dados e então interpretados por especialistas ou profissionais da área – bottom-up.
"O seu principal objetivo não é produzir um saber sobre um indivíduo identificável, mas usar um conjunto de informações pessoais para agir sobre similares", diz Fernanda Bruno, doutora em comunicação e professora da UFRJ, em seu livro Máquinas de ver, Modos de Ser. "O perfil atua, ainda, como categorização de conduta, visando à simulação de comportamentos futuros."
Uma das líderes nesse setor no Brasil é a Navegg. A empresa monitora cerca de 400 milhões de pessoas e tem scripts em 100 mil sites. Prometendo aos clientes uma "visão holística do internauta", ela oferece diversos serviços de inteligência de dados, behavioral targeting (monitoramento de comportamento) e de análises de perfis de navegação.
A empresa é uma das poucas do ramo que conta com a possibilidade de o usuário checar qual é o próprio próprio perfil e, se quiser, parar de ser monitorado. A possibilidade é uma boa prática da empresa, já que no Brasil não há regulamentação para definir esse tipo de limite de monitoramento. A empresa não respondeu às questões enviadas pelo Chupadados, mas seu site oferece informações relevantes.
A Navegg “analisa e segmenta internautas em doze critérios: gênero, idade, escolaridade, classe social, estado civil, conteúdos de interesse, intenção de compra, comportamento, marcas, área de atuação, tecnologia (conexão, dispositivos, navegadores e sistemas operacionais) e localização (país, cidade e região)”. Assim, a empresa pode ter analisado Fernanda e determinado que:
- Ela se enquadra no segmento Paternidade (“internautas que acessam conteúdo para a educação dos filhos, cuidados com bebês, gravidez, entre outros”) por ter visitado sites de significado de nomes ou feito buscas sobre sintomas ou condições específicas da gravidez.
- Ela também faz pesquisas frequentes sobre tópicos relacionados a programação e tecnologia, então certamente faz o tipo Desenvolvimento de Software (“Internautas que acessam sites sobre desenvolvimento de software, linguagem de programação, banco de dados, redes de computadores e segurança da informação, etc”).
- Seu trabalho em uma ONG provavelmente a inclui no segmento Causas Sociais (“internautas que acessam conteúdo sobre causas sociais, caridade, filantropia, entre outros”).
Juntamente com o avanço das tecnologias de monitoramento e data mining, uma indústria associada à de tracking vem se desenvolvendo para coletar, processar e revender esses dados, tecendo elos entre os diferentes bancos de dados.
São as chamadas data brokers, ou “corretoras de dados”. Comprando e vendendo dados gerados na rede e fora dela (como em cadastros de lojas, serviços de proteção ao crédito e até programas sociais do governo) essas empresas conseguem gerar perfis e segmentar a população de uma maneira ainda mais precisa. Assim, as compras de Fernanda no supermercado e na farmácia, onde ela usa seu cartão de fidelidade para ganhar descontos (ou até mesmo seu cartão de crédito), podem ter contribuído para que lhe fossem oferecidos produtos para grávidas.
Fantasmas e estereótipos
Os perfis gerados, normalmente, correspondem a comportamentos, gravidezes e bebês que existem. Mas, em alguns casos, não - quando acontecem abortos espontâneos, por exemplo. Em seu livro "Healthcare and Big Data - Digital Specters and Phantom Objects", a socióloga britânica Mary Ebeling descreve como o mercado mantém vivo um bebê que já morreu através de dados, propagandas direcionadas, newsletters e outros tipos de estratégias comerciais.
É um "marketing baby". "Um bebê preenchido por desejo", ela diz. Desejo de roupas, leite em pó, cadeirinha para carro, armazenamento de células-tronco do cordão umbilical e outros tipos de produtos e serviços oferecidos incessantemente para sua mãe, mesmo que ele nunca tenha nascido. A pesquisadora, que viveu isso na pele, coletou histórias de outras mulheres que tentaram se livrar - em vão - das ofertas para uma criança que já não iria nascer. Há casos de bebês de marketing que nasceram após a criação de um perfil em um fórum de mães, outros de cadastros em farmácias e, em todos, as mulheres tiveram dificuldade para sair dos perfis em que foram incluídas, mesmo sem terem tido seus bebês.
Como não há controle na maneira como os dados são coletados e cedidos a terceiros, a simples remoção do cadastro ou login inicial que enquadrou as mulheres no perfil "mães" não basta para mudar o status. No livro, a autora mostra a complexidade do sistema e a falta de poder das usuárias sobre suas próprias informações, que são utilizadas para enquadrá-las em um perfil em que elas não estão mais (ou não querem estar).
As situações descritas por Ebelin são um dos aspectos mais cruéis do sistema de profiling, mas ainda há outras consequências. Como o processo é uma via dupla - é alimentado do comportamento dos usuários e também alimenta essa mesma lógica, exibindo conteúdo e anúncios relacionados a esses mesmos temas -, ele acaba exacerbando comportamentos e padrões que já existem na sociedade.
No caso da maternidade, por exemplo, ele reforça e acirra os papéis pré-determinados pela sociedade patriarcal da mulher como principal cuidadora e responsável pelos filhos (e, depois, de reconquistar o corpo pré-gravidez e o próprio marido, segundo os anúncios vistos por Fernanda). "Não apenas fornecem informações que dizem o que a gente é, mas jogam de volta coisas que retroalimentam esse perfil", diz Fernanda.
Quando Fernanda se deu conta do nível de monitoramento e do retorno de marketing, ela conversou com o seu parceiro, pai da criança. Embora ele tenha procurado por informações e produtos relacionados à paternidade e bebês, ele permaneceu quase imune aos anunciantes. "Eu acho que é porque ele é homem", sugere Fernanda. Para o mercado, homens não se interessam pelos filhos.
"A gente só é submetido a coisas que reforçam as mesmas características. Porque isso é melhor para o mercado. Quando mais exacerbado um perfil é, mais fácil vender coisas." Fernanda*, 31, mãe e pesquisadora na área de tecnologia e sociedade
Mulheres são historicamente classificadas e representadas de maneira a servir, de alguma forma, o patriarcado. Seja como objetos sexuais ou cumprindo um papel específico - mãe, avó ou profissional bem sucedida -, a representação feminina é sempre ligada a estereótipos, com pouco espaço para a complexificação. "A tecnologia permite que se agrave uma coisa que a sociedade já tem. De repente eu virei uma mulher mãe que não quer saber mais sobre política e tecnologia", diz Fernanda.
Além de reforçar estereótipos, o que por si só já preocupa, a classificação em perfis também tem consequências políticas - as mesmas técnicas podem ser utilizadas para identificar possíveis manifestantes ou dissidentes políticos, por exemplo.
Os recentes casos de policiais infiltrados em apps para investigar possíveis ativistas, como o de "Balta Nunes" em São Paulo e uma página no Facebook que fingia ser parte do grupo Maré Vive no Rio de Janeiro mostram que não há muitos limites para a vigilância. Com a facilidade de monitoramento e identificação criada pelo mercado, o Estado também pode fazer a festa da vigilância sobre nossa navegação.
E isso pode ir bem além de anúncios não requisitados. Há evidências de que o uso de sofisticadas ferramentas de profiling e análise de dados em larga escala foram fundamentais para a vitória de Donald Trump nas últimas eleições nos EUA. E pode piorar: esse tipo de ferramenta tem potencial de exacerbar o autoritarismo, dando margem à ascensão do fascismo.
Tem gente que diz que isso já está acontecendo - Kate Crawford, pesquisadora da Microsoft, é uma delas. Ela cita como exemplo um software chinês que diz que pode identificar possíveis criminosos através do rosto (um retorno assustador e massivo à frenologia, pseudociência enterrada no século 19) e uma empresa chamada Faceception, que diz reconhecer, também através do rosto, o comportamento e o perfil social de uma pessoa.
Dá para ter uma ideia do que poderia acontecer se toda essa tecnologia cair nas mãos erradas - o marketing invasivo é apenas o começo.
Como driblar todo esse monitoramento
O Brasil até hoje não tem uma lei de proteção de dados pessoais, o que torna ainda mais difícil saber que tipo de informações as empresas estão guardando sobre nós. Mas o cenário pode mudar: está em discussão na Câmara dos Deputados o PL5276/16, um dos projetos de lei de dados pessoais que tem o melhor potencial de solucionar parte destas questões.
Se aprovado, ele vai assegurar que o uso desses dados seja feito com consentimento informado e em concordância com alguns princípios, como o da finalidade, necessidade e proporcionalidade (ou seja, seus dados só podem ser usados para o mesmo fim para o qual você os cedeu. Também vai garantir que a anonimização seja eficiente, impedir que o uso do dado possa lhe causar algum dano e prevê, ainda, algum mecanismo de fiscalização e ressarcimento em caso de dano.
Para ajudar a impulsionar esse projeto de lei, a Coalizão Direitos na Rede está mobilizando e compartilhando informações pela hash #SeusDadosSaoVoce - siga e colabore compartilhando e ajudando mais gente a entender a importância do tema.
Enquanto a lei não vem, porém, nossa navegação segue desprotegida e classificada, enquadrada e vendida por empresas. Há algumas medidas, no entanto que você pode tomar para tentar driblar toda essa vigilância.
1. Use bloqueadores de anúncios e trackers no seu navegador. No Android, o Block This é uma solução livre, gratuita e cross-browser / cross-app (mas indisponível na Play Store uma vez que a Google a baniu de sua loja; deve-se instalar pelo website) e o AdGuard (grátis por 14 dias, ). No Firefox, use o Privacy Badger e uBlock Origin. Para o iOS, há o Better (pago, focado em bloquear behavioral tracking, Safari) e o Firefox Focus. Para Chrome e Firefox, instale tanto o uBlock Origin (que atua através de listas de URLs que servem anúncios/trackers/malware mantidas por voluntáries) quanto o Privacy Badger (atua com uma inteligência interna que bloqueia scripts que estão monitorando em diferentes sites, não depende de listas). Para todas as plataformas há o Brave, que além de bloquear anúncios e trackers propõe um método alternativo de pagamento aos websites;
2. Tenha perfis separados do navegador para diferentes tarefas. Dicas de como fazer no Firefox e no Chrome;
3. Restrinja os Cookies: desabilitar flash cookies ou super cookies nas configurações do navegador, habilitar a auto-destruição de cookies, que faz os cookies serem destruídos assim que você fecha a janela (só para Firefox);
4. Navegue com o Tor. Em vez de bloquear os trackers, por anonimizar a navegação, o Tor torna impossível ligar seus passos a você. Para o computador, você pode baixar em torproject.org; no Android você deve instalar os apps Orfox (o navegador) e Orbot (o proxy);
5. Teste. Tomou alguma dessas medidas? Teste a segurança do seu browser usando o panopticlick.
